tf.estimator API
텐서플로 estimator API는 훈련, 예측(추론), 평가와 같은 머신 러닝 작업의 기본 단계를 캡슐화한다.
캡슐화가 기본적으로 잘 되어 있으며, 확장성도 높다.
tf.estimator API를 사용하면, 주요 코드를 변경하지 않고도 다양한 플랫폼에서 모델을 실행 가능하도록 지원
상용 애플리케이션, ‘제품화 단계’에 적합하다.
텐서플로는 널리 사용하는 일부 머신 러닝과 딥러닝 구조를 미리 구현한 추정기를 제공한다.
특정 방법이 어떤 데이터셋이나 문제에 적용할 수 있는지 빠르게 확인하는 것 같은 비교 연구에 유용하다.
특성 열
머신 러닝과 딥러닝 애플리케이션에는 다양한 종류의 특성이 있다(연속특성(회귀), 순서가 없는 범주형 특성, 순서가 있는 범주형 특성)
텐서플로 API에서는 수치형 데이터를 부동 소수 형태의 연속적인 데이터로 나타낸다.
특성 집합은 다양한 특성 종류가 혼합되어 구성되어 있다. 텐서플로 추정기는 이러한 모든 종류 특성을 다루도록 설계되어 있다.
하지만, 각 특성이 추정기에서 어떻게 해석되어야 하는지 지정해 주어야 한다.
Auto MPG 데이터셋
갤런당 마일(MPG) 단위로 자동차의 연료 효율성을 예측하는 문제를 위한 데이터셋이다.
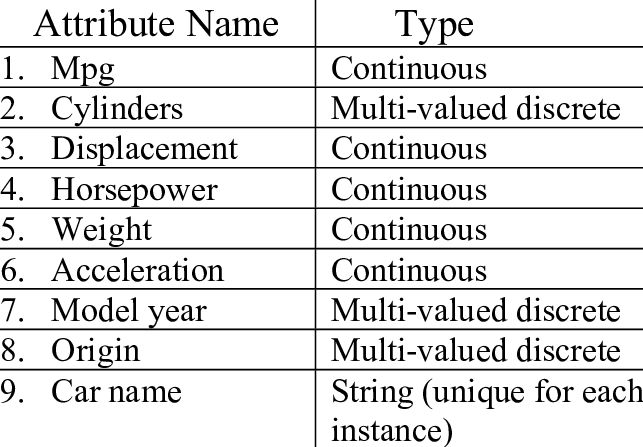
Auto MPG 데이터셋 중 다섯 개의 특성(cylinders, displacement, horsepower, weight, accleration은 수치형(연속적인) 특성이다.
model year은 순서가 있는 범주형 특성, origin은 순서가 없는 특성이다.(US:1, EU:2, JP:3)
import pandas as pd
import numpy as np
import tensorflow as tf
dataset_path=tf.keras.utils.get_file("auto-mpg.data", ("http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"))
column_names=['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'ModelYear', 'Origin']
df=pd.read_csv(dataset_path, names=column_names, na_values='?', comment='\t', sep=' ', skipinitialspace=True)
df=df.dropna()
df=df.reset_index(drop=True)
import sklearn
import sklearn.model_selection
df_train, df_test=sklearn.model_selection.train_test_split(df, train_size=0.8)
train_stats=df_train.describe().transpose()
numeric_column_names=[
'Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration']
df_train_norm, df_test_norm=df_train.copy(), df_test.copy()
for col_name in numeric_column_names:
mean=train_stats.loc[col_name, 'mean']
std=train_stats.loc[col_name, 'std']
df_train_norm.loc[:, col_name]=(df_train_norm.loc[:, col_name]-mean)/std
df_test_norm.loc[:, col_name]=(df_test_norm.loc[:, col_name]-mean)/std
df_train_norm.tail()
>>> df_train_norm.tail()
MPG Cylinders Displacement ... Acceleration ModelYear Origin
184 27.0 -0.864364 -0.888349 ... -0.065178 76 2
375 36.0 -0.864364 -0.832382 ... -0.351501 82 3
37 14.0 1.488210 1.434280 ... -1.246262 71 1
282 20.6 0.311923 0.268302 ... 0.400098 79 1
366 29.0 -0.864364 -0.571203 ... 0.185356 82 1
[5 rows x 8 columns]
tf.keras.utils.get_file
/Users/csian/.keras/datasets/auto-mpg.data
numeric_column_names에 수치형 데이터의 특성을 담고, 표준화했다.(float type)
tensorflow의 feature_column 함수를 이용한 열 데이터 구조 변환
numeric_features=[]
for col_name in numeric_column_names:
numeric_features.append(tf.feature_column.numeric_column(key=col_name))
model year 정보를 그룹으로 묶어 버킷(bucket)으로 나눔_순서있는 범주
버킷
0: year<73
1: 73<=year<=76
2: 76<=year<=79
3: year>=79
(-infinite, 73), [73, 76), [76, 79), [79, infinite)
feature_year=tf.feature_column.numeric_column(key='ModelYear')
bucketized_features=[]
bucketized_features.append(tf.feature_column.bucketized_column(source_column=feature_year, boundaries=[73, 76, 79]))
Origin 정보 리스틀 정의_순서 없는 범주
데이터가 범주 이름이라면 tf.feature_column.categorical_column_with_vocabulary_list를 이용해서 고유 범주 이름을 입력으로 제공
범주 리스트가 너무 크다면 tf.feature_column.categorical_column_with_vocabulary_file을 사용할 수 있다.
(모든 범주/단어가 들어 있는 파일을 제공하여 메모리에 모든 가능한 단어 목록을 유지할 필요가 없다.)
특성이 [0, num_categories) 범위의 범주 인덱스로 매핑되어 있다면, tf.feature_column.categorical_column_with_identity 함수를 사용
(auto MPG 모델의 Origin은 1, 2, 3으로 주어져 있기 때문에 범주 인덱스에 맞지 않는다.(0, 1, 2로 되어야 한다.))
feature_origin=tf.feature_column.categorical_column_with_vocabulary_list(
key='Origin', vocabulary_list=[1, 2, 3])
DNNClassifier와 DNNRegress 같은 추정기는 밀집 열(dense column)만 받는다.
embedding_column 함수를 이용해서 임베딩 열로 바꾸거나, indicator_column 함수로 인디케이터(indicator) 열로 바꿀 수 있다.
(인디케이터 열은 인덱스를 원-핫 인코딩된 벡터로 바꾼다. ex 인덱스0->[1, 0, 0])
(임베딩열은 각 인덱스를 float 타입의 랜덤한 수치 벡터로 매핑한다.)
인디케이터 열로 범주형 특성을 밀집 열로 변형
categorical_indicator_features=[]
categorical_indicator_features.append(tf.feature_column.indicator_column(feature_origin))